
'DATA BASE (DB) > PostgreSQL' 카테고리의 다른 글
| 저장 프로시저 (Stored Procedure, SP) (0) | 2022.05.26 |
|---|---|
| 스키마 소유자(owner)변경하기 (0) | 2022.03.27 |
| PostgreSQL 베큠Vacuum (0) | 2022.03.22 |
| PostgreSQL DB Dump 명령어 (0) | 2022.03.06 |
| 임시PK 만들기위해 컬럼중복값 확인작업 (0) | 2019.10.22 |
| 저장 프로시저 (Stored Procedure, SP) (0) | 2022.05.26 |
|---|---|
| 스키마 소유자(owner)변경하기 (0) | 2022.03.27 |
| PostgreSQL 베큠Vacuum (0) | 2022.03.22 |
| PostgreSQL DB Dump 명령어 (0) | 2022.03.06 |
| 임시PK 만들기위해 컬럼중복값 확인작업 (0) | 2019.10.22 |

<div style="margin-top:10px;">\r\n.*\r\n.*\r\n.*\r\n.*</div>$
| JS 모듈시스템 (ES모듈, CommonJS모듈) (0) | 2022.09.15 |
|---|---|
| front 개념정리 및 복기 (출처: 짐코딩 GYM CODING) (0) | 2022.09.05 |
| JS Prototype (2) | 2022.07.11 |
| 유사한 name값 input 태그 활용 (feat. 체크박스응용) (0) | 2022.06.10 |
| react.js 개념정리 (0) | 2021.03.04 |
상세페이지의 닫기 function을 일괄 주석처리
$('#btnClose').on('click', function() {
$("#tblList tbody tr").removeClass("selected");
$("#divInfo").hide();
});파일검색시 Regular expression 체크박스 선택후
\$\(\'\#btnClose\'\)\.on\(\'click\'\, function\(\) \{ \r\n.*\r\n.*\r\n\}\)\;$
> 특수문자기호 앞에는 \(역슬러리) 처리
/* $0 */
> $0 검색 결과의 검출된 대상을 지칭
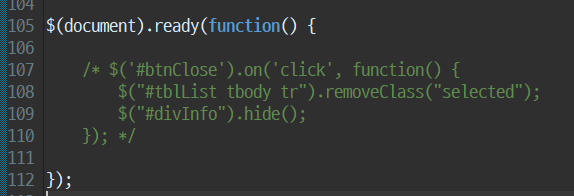
일괄 주석처리
| CI/CD (0) | 2022.09.12 |
|---|---|
| GIS WMS, WFS (0) | 2022.07.17 |
| svn: E204900 (0) | 2022.05.09 |
| linux 사용자계정이 변경 안되는 경우 (1) | 2022.04.26 |
| 톰캣 스케쥴러 중복실행되는 문제 (0) | 2020.03.17 |
분리된 하나의 파일을 모듈(module)이라고 부르는데, 모듈은 대게 클래스 하나 혹은 특정한 목적을 가진 여러개의 함수를 포함하는 라이브러리로 구성되어 있음.
> ES6에 도입된 자바스크립트 모듈로 <script> 태그에 type="module" 속성을 추가해주면, 해당 파일은 모듈로서 동작.
모듈을 외부에서 사용할수 있도록 내보낼때는 export, export default 와 같은 키워드를 사용하며, 외부에서 모듈을 불러 올때는 import 를 사용하여 모듈을 불러온다.
> NodeJS 환경에서 자바스크립트 모듈을 사용하기 위해 만들어진 모듈 시스템. 모듈을 외부에서 사용할 수 있도록 내볼때는 export, module.export 와 같은 키워드를 사용하며, 외부에서 불러올때는 require 를 사용하여 모듈을 불러옴,
CommonJs 모듈 시스템을 채택했던 NodeJS환경에서 ES Module을 사용하려면 babel과 같은 트랜스파일러(transpiler)를 사용했어야 하는데, NodeJS 13.2 버전부터 ES모듈 시스템에 대한 정식 지원이 시작됨으로서 별다른 도구 필요 없이 NodeJS에서 ES Module을 사용할수 있게 되었다고 함.
출처 : https://www.youtube.com/watch?v=5NXEXkIrkAk
| Regular expression jsp tag 검색 (0) | 2023.10.24 |
|---|---|
| front 개념정리 및 복기 (출처: 짐코딩 GYM CODING) (0) | 2022.09.05 |
| JS Prototype (2) | 2022.07.11 |
| 유사한 name값 input 태그 활용 (feat. 체크박스응용) (0) | 2022.06.10 |
| react.js 개념정리 (0) | 2021.03.04 |
CI/CD
application 개발부터 배포 때까지 이 모든 단계들을 자동화를 통해서 조금 더 효율적이고 사용자에게 빈번이 배포할 수 있도록 만드는 것을 의미.
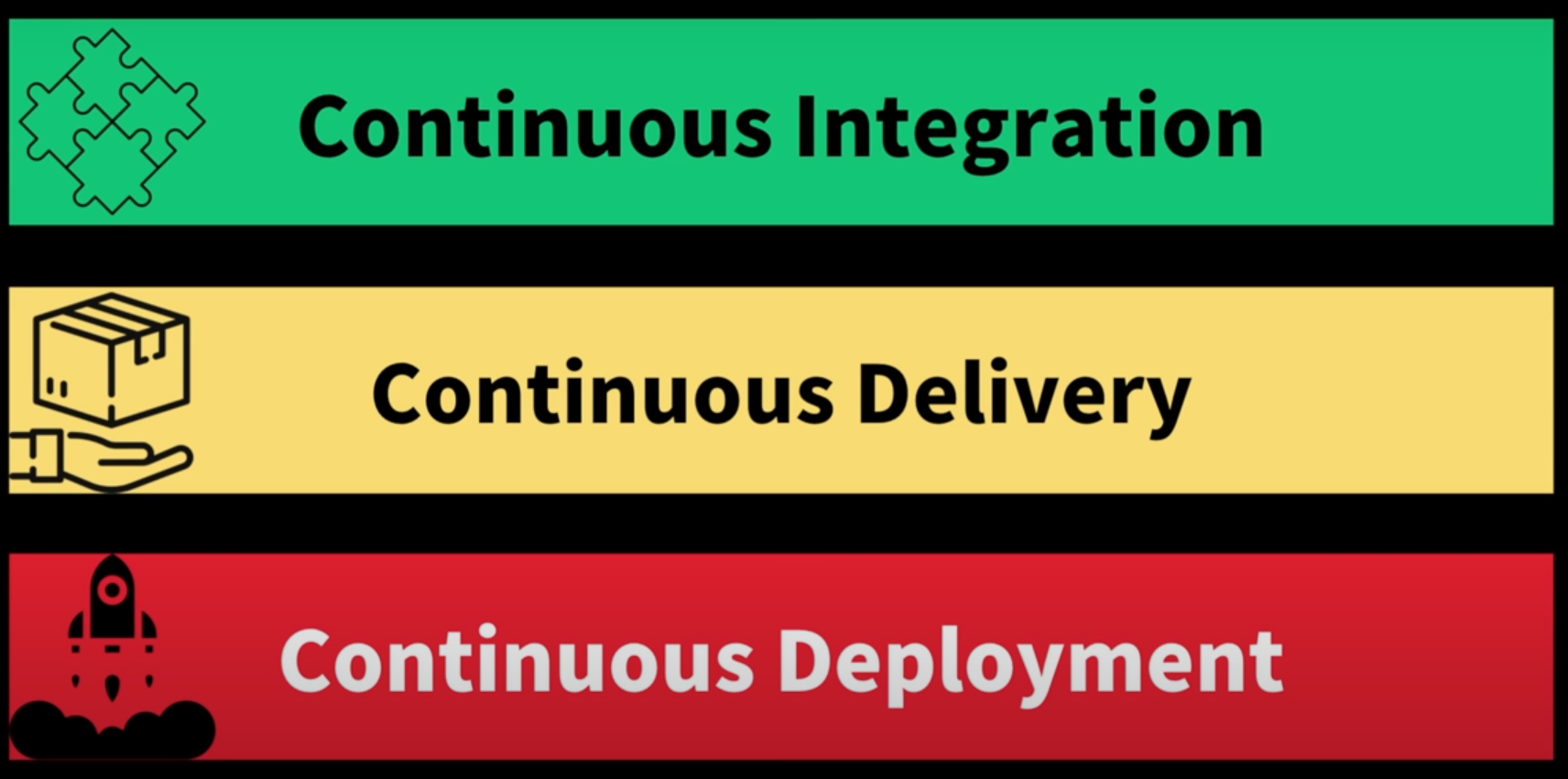
CI - 버그수정 또는 새로만드는 기능들이 메인 레파지토리에 주기적으로 빌드되고 테스트되어 merge 되는것을 의미.
CD - 마지막 배포단계에서 어떻게하면 자동화로 배포될지를 고민하는 단계이며 최종단계가 자동화가 되어있는지 아닌지에 따라서 Delivery(일부 수동적) 일지 Deployment(자동화)일지 나뉜다.

| JSP Regular exprssion 정규식 변환 검색 후 주석처리 (0) | 2023.09.21 |
|---|---|
| GIS WMS, WFS (0) | 2022.07.17 |
| svn: E204900 (0) | 2022.05.09 |
| linux 사용자계정이 변경 안되는 경우 (1) | 2022.04.26 |
| 톰캣 스케쥴러 중복실행되는 문제 (0) | 2020.03.17 |
Spring 개발을 하다보면 mapper.xml 에 간혹 ' WHERE 1=1 ' 을 보게 된다.
where 1=1 은 어떤이유 때문에 소스에 사용 되는지와 사용하지않는다면 어떤 대안이 있는지 알아볼까 한다..
( 필자는 where 1=1 을 사용시 DB실행에 불필요한 수식연산이 들어가여 자원을 잡아먹어 선호하지 않는 의견을 몇번 들어보긴 하였다.. )
WHERE 1=1 참(ture)을 의미
쿼리의 조건을 동적으로 사용하기위해 사용한다고 한다.
하지만, DLETE(삭제), UPDATE(수정) 기능을 수행하는 쿼리에서는 null판별이 옳바르게 전처리 작업이 수행되지 않는 상황에서 삭제나 수정 기능에 사용한다면 원치않는 결과를 초래할수 있다고한다. 왜냐하면 1=1 은 참이기때문에 모든 데이터를 삭제하거나, 모든데이터를 수정하는 일이 발생할수 있기때문이다.
정리하자면, 대부분에 동적인 상황을 고려하여 WHERE 1=1을 사용하는 경우가 대부분의 사용하는 이유가 될것이라고 필자는 생각한다, 하지만 의도치않는 예외적인 상황이 발생한다는 점을 고려한다면 좋은 방법은 아닌것이라고 생각이된다.
WHERE 1=1 에대해서 사용하는 이유와 반대로 WHERE 1=1 을 사용하지 말아야 한다는 이유를 찾다가 잘 정리된 2개의 블로그 게시글이 있어 공유한다. (판단은 본인이...)
[MYSQL] WHERE 1=1 사용하는 이유?? 주의사항으로는??
안녕하세요, 오늘은 MYSQL 질의문에서 WHERE 1=1을 사용하는 이유에 대해서 알아보도록 하겠습니다. 다른 개발자가 개발한 프로젝트를 유지 보수하거나, 처음 개발자로 입문하여 선임들이 작성한
ssd0908.tistory.com
OKKY - 동적 쿼리 만들때 where 1=1 쓰면 안되는 이유에 대하여..
동적 쿼리 만들때 where 1=1을 쓰지 말아야 하는 이유에 대하여.. 안녕하세요.. 예전에 이 부분에 대해 댓글을 달은적이 있었습니다.. 그때 저는 where 1=1을 쓰면 안된다고 했습니다..잠재적 버그를
okky.kr
WHERE 1=1 의 대안으로는 <where> 태그와 <c:if> 태그를 사용하여 대체하는 방법을 권고한다.
예시
WHERE 1=1
and user_id = #{userId}
<where>
<if test="userId != null and userId != ' ' ''>
and user_id = #{userId}
</if>
</where>
마지막으로 해당 mybtais 동적SQL에 대한 자세한 내용은 mybatis 공식사이트에서 확인할 수 있다.
mybatis – MyBatis 3 | Dynamic SQL
Dynamic SQL One of the most powerful features of MyBatis has always been its Dynamic SQL capabilities. If you have any experience with JDBC or any similar framework, you understand how painful it is to conditionally concatenate strings of SQL together, mak
mybatis.org
: 문서 객체 모델
https://developer.mozilla.org/ko/docs/Web/API/Document_Object_Model/Introduction
DOM 소개 - Web API | MDN
이 문서는 DOM에 대한 개념을 간략하게 소개하는 문서이다: DOM 이 무엇이며, 그것이 어떻게 HTML, XML (en-US) 문서들을 위한 구조를 제공하는지, 어떻게 DOM 에 접근하는지, API 가 어떻게 사용되는지에
developer.mozilla.org
: 브라우저를 제어하기 위한 인터페이스
Window - Web API | MDN
Window 인터페이스는 DOM 문서를 담은 창을 나타냅니다. document 속성이 창에 불러온 DOM 문서를 가리킵니다. 반대로, 주어진 문서의 창은 document.defaultView를 사용해 접근할 수 있습니다.
developer.mozilla.org



* 동기,비동기 설명 https://www.youtube.com/watch?v=sN4E9_u7xQk
대부분의 경우 this의 값은 함수를 호출한 방법에 의해 결정된다고 한다.. (this는 호출한 놈?이라고 이해하며, 호출한 행위가 없을경우 기본값으로는 window객체 라고한다.) 단, 위의 경우와 달리 아래와 같이 예외적인 상황도 존재한다.
* window객체 : 브라우저에서 제공하는 전역 객체
default this = window 객체, 함수를 호출한적이 없을 경우 기본적으로 this는 window 객체
220906 추가내용 :
bind() 메서드 : this를 설정할수있는 메서드 단, bind는 단 1번만 this를 설정할 수 있다.
화살표 함수(arrow function)는 자신을 포함하고 있는 외부 Scope에서 this를 계승받는다. (화살표 함수에서 this는 자신을 감싼 정적 범위)
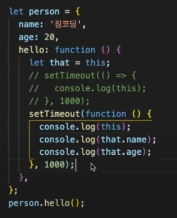
엄격모드?(Strict Mode)에서는 함수를 호출한적이 없을 경우 기본값을 window로 하지않고 undefined로 정의 한다.
출처 : https://www.youtube.com/c/gymcoding
짐코딩의 CODING GYM
실용적인 코딩채널 CODING GYM 💪🏋️♀️ 【짐코딩 클럽 온라인 강의 🎉】 👉 https://edu.gymcoding.co 【광고 및 제휴 문의 😙】 👉 bruce.lean17@gmail.com 【커피 한잔 후원 🙂】 👉 https://toon.at/donate
www.youtube.com
| Regular expression jsp tag 검색 (0) | 2023.10.24 |
|---|---|
| JS 모듈시스템 (ES모듈, CommonJS모듈) (0) | 2022.09.15 |
| JS Prototype (2) | 2022.07.11 |
| 유사한 name값 input 태그 활용 (feat. 체크박스응용) (0) | 2022.06.10 |
| react.js 개념정리 (0) | 2021.03.04 |
전체쿼리 결과 집합을 쉼 없이 연속적으로 전송하지 않고 사용자로 부터 Fetch Call이 있을때 마다 일정량씩 나누어 전송하는 것을 '부분범위 처리'라고 한다.
인덱스는 항상 정렬된 상태를 유지하므로 전체 데이터를 정렬하지 않고도 정렬된 상태의 결과집합을 바로 전송할 수 있다.
대량 데이터를 파일로 내려받는다면 데이터를 모두 전송해야하므로 가급적 Array Size를 크게 설정해야한다. Array Size를 조정한다고 해서 전송해야 할 총량이 변하진 않지만, Fetch Call 횟수를 그만큼 줄일수 있으며, 반대로 앞쪽 일부 데이터만 Fetch하다가 멈추는 프로그램이라고 할 경우 Array Size를 작게 설정하는 것이 유리하다.(불필요하게 많은 데이터를 전송하고 버리는 비효율을 줄일수 있음.)
모든 DBMS는 데이터를 조금씩 나눠서 전송한다. 즉, 부분범위 처리 방식으로 결과집합을 전송한다. 이 특징을 이용해 중간에 멈췄다가 사용자의 추가 요청이 있을 때마다 데이터를 가져오도록 구현하고 안하고의 차이는 책의 저자가 말하길 DBMS 클라이언트 프로그램을 개발하는 개발자의 몫이라고 말한다.
개발 프레임워크에 미리 부분범위 처리 된 구현 기능을 활용하면 된다고 한다.
온라인 트랜잭션을 처리하는 프로그램을 말하며, 일반적으로 소량 데이터를 읽고 갱신한다. (하지만 항상 소량 데이터만 조회하는것은 아님)
수천수만 건을 조회하는 경우에는 많은 테이블 랜덤 액세스가 발생하기 때문에 제 성능을 내기 어려울수 있다. 버퍼캐시히트율이 좋다면 빠른 성능을 보일수 있지만, 아닌 경우도 존재하기 때문이다.
그러나 OLTP성 업무에서 쿼리 집합이 아주 많을 때 사용자가 모든 데이터를 일일이 다 확인하지 않는다. 특정한 정렬 순서로 상위 일부 데이터만 확인한다. (ex. 은행계좌 입출금 조회, 뉴스 또는 게시판 등등..) 주로 목록을 조회하는 경우. 이런 경우 항상 정렬 상태를 유지하는 인덱스를 이용하면, 정렬 작업을 생략하고 앞쪽 일부 데이터를 아주 바르게 보여줄수 있다. (인덱스와 부분범위 처리를 잘 활용한다면 OLTP환경에서 극적인 성능 개선 효과를 얻을수 있다고 함.)
해당 내용은 추후 5장 3절에서 다룬다고 함..
인덱스를 이용해 테이블을 액세스하다가 버퍼 캐시에서 블록을 찾지 못하면 일반적으로 디스크 블록을 바로 읽는데(오라클11g 까지), 배치I/O기능이 작동하면 테이블 블록에 대한 디스크 I/O Call을 미뤘다가 읽을 블록이 일정량 쌓이면 한꺼번에 처리한다. (오라클12c 이후 해당)
(* 12c에 도입된 일반 배치 I/O와 NL조인에 작동하는 기존 배치I/O는 파라미터, 힌트, 실행계획 표현방식이 모두 다르다.)
배치I/O를 통해 얻을수 있는 성능 이점이 많은에도 불구하고 시스템레벨에서 이를 비활성화 하는 경우가 종종있다. 이 기능을 비활성화하는 이유는 '필요한' order by를 생략한 SQL패턴 때문라고 한다. SQL에 order by가 없으면 결과 집합의 정렬 순서를 보장할 필요가 없으므로
옵티마이저가 배치I/O를 선택할 수 있고, 출력된 결과집합의 정렬 순서가 매번 다를수 있다.
배치I/O 기능이 작동하면 인덱스를 이용해서 출력하는 데이터 정렬 순서가 매번 다를수 있다는 사실에 주목해야 함..

| SQL튜닝 (인덱스 구조 테이블) (0) | 2022.08.21 |
|---|---|
| SQL튜닝 공부내용 (feat. 인덱스 튜닝) (1) | 2022.08.15 |
| 05-01 SQL튜닝 공부내용 (테이블 액세스 최소화_1) (0) | 2022.05.01 |
| 22-03-19 주말공부 (인덱스 확장기능 사용법) (0) | 2022.03.20 |
| 22-02-20 공부내용 정리 (0) | 2022.02.20 |
@RequestBody : 클라이언트가 전송하는 JSON(application/json) 형태의 HTTP Body를 JAVA객체로 변환시켜주는 역할,
Body가 존재하지 않는 HTTP Get 메소드에 @RequestBody를 활용하려고 한다면 에러가 발생한다. @RequestBody로 받는 데이터는 Spring에서 관리하는 MessageConverter 중 MappingJackson2HttpMessageConverter를 통해 JAVA객체로 변환하는데, 이는 ObjectMapper 라는 클래스를 이용한다.
@RequestParam : 1개의 HTTP요청 파라미터를 받기 위해서 사용한다. @RequestParam은 필수 여부가 true이므로 반드시 해당 파라미터가 전송되어야 하며, 파라미터가 전송되지 않으면 400에러를 발생한다. (필수값이 아닌경우 required를 false로 설정하는 방법이 있으며, defaultValue옵션을 사용하면 기본값 역시 지정 가능하다.)
@ModelAttribute : 클라이언트가 전송하는 multipart/form-data 형태의 HTTP Body와 HTTP 파라미터의 값들을 생성자나 Setter를 통해 주입하기 위해 사용된다. @ModelAttribute에는 매핑시키는 파라미터의 타입이 객체의 타입과 일치하는지를 포함한 다양한 검증(Validiation) 작업이 추가적으로 진행되는데, 예를 들어 게시물의 번호를 저장하는 int형 index 변수에 "1번" 이라는 String형을 넣으려고 한다면, BindException이 발생하게 된다.
@ModelAttribute을 사용해서 특정 Parameter 값 만을 가져올 수도 있다.
* ObjectMapper의 동작과정 : ObjectMapper는 Json 메세지를 자바 객체로 변환하는 과정에서 객체의 기본 생성자를 통해 객체를 생성하고, 내부적으로 Reflection을 사용한다. 그래서 반드시 @Setter가 필요한 것은 아닌데, @Getter나 @Setter 혹은 @JsonInclude 등 필드에 있는 변수들의 이름을 찾기 위한 메소드들을 필요로 한다.
그러므로 기본생성자 + @Getter로 클래스를 구현해주면 @Setter가 없어도 값이 바인딩된다.
출처: https://mangkyu.tistory.com/72 [MangKyu's Diary:티스토리]MangKyu's Diary:티스토리]
| Eclipse(& STS)에 lombok.jar(롬복) 설치방법 (0) | 2018.01.15 |
|---|---|
| svn 소스변경기록 확인 (0) | 2018.01.02 |
오라클에서 랜덤 엑세스가 아예 발생하지 않도록 테이블을 인덱스 구조로 생성하는 방법을 IOT(Index-Organized Table)이라 함.
(MS-SQL Server 에서는 '클러스터형 Clustered 인덱스'라고 함.
테이블을 찾아가기 위한 ROWID를 갖는 일반 인덱스와 달리 IOT는 그자리에 테이블 데이터를 갖는다.(즉, 테이블 블록에 있어야 할 데이터를 인덱스 리프 블록에 모두 저장하고 있다. IOT에서는 '인덱스 리프 블록이 곧 데이터 블록' 이다. )
일반 테이블은 '힙 구조 테이블'이라고 부른다. 일반 힙 구조 테이블에 데이터를 입력할 때는 랜덤 방식을 사용한다. 반면, IOT는 인덱스 구조 테이블이므로 정렬 상태를 유지하며 데이터를 입력한다.
IOT는 인위적으로 클러스터링 팩터를 좋게 만드는 방법 중 하나이며, Between이나 부등호 조건으로 넓은 범위를 읽을때 유리하다. 또한, 데이터 입력과 조회 패턴이 서로 다른 테이블에도 유용하다.
클러스터 키값이 같은 레코드를 한 블록에 모아서 저장하는 구조. 한 블록에 모두 담을 수 없을 때는 새로운 블록을 할당해서 클러스터 체인으로 연결한다. 추가적으로 여러 테이블 레코드를 같은 블록에 저장할 수도 있는데, 이를 '다중 테이블 클러스터' 라고 함. (일반 테이블은 하나의 데이터 블록을 여러 테이블이 공유할 수 없음)
클러스터에 테이블을 담기 전에 아래와 같이 클러스터 인덱스를 반드시 정의해야 한다. 클러스터 인덱스는 데이터 검색 용도로 사용할 뿐만 아니라 데이터가 저장될 위치를 찾을 때도 사용하기 때문..
클러스터 인덱스도 일반 B*Tree 인덱스 구조를 사용하지만, 테이블 레코드를 일일이 가리키지 않고 해당 키 값을 저장하는 첫 번째 데이터 블록을 가르킨다는 점이 다르다. 따라서 클러스터 인덱스의 키값은 항상 유니크하다(=중복값이 없다)
해시 클러스터는 인덱스를 사용하지 않고 해시 알고리즘을 사용해 클러스터를 찾아간다는 점만 다르다.
| 3.2부분범위 처리 활용 (0) | 2022.09.04 |
|---|---|
| SQL튜닝 공부내용 (feat. 인덱스 튜닝) (1) | 2022.08.15 |
| 05-01 SQL튜닝 공부내용 (테이블 액세스 최소화_1) (0) | 2022.05.01 |
| 22-03-19 주말공부 (인덱스 확장기능 사용법) (0) | 2022.03.20 |
| 22-02-20 공부내용 정리 (0) | 2022.02.20 |